This post begins with a description of the State Management Problem and various solutions to it offered by today's programming languages. The final section details the solution provided by version 0.8 of the Tridash programming language. The section contains a complete code example of a simple application comprising a counter which is incremented whenever a button is pressed.
The State Management Problem
When developing an application with an interactive user interface, one of the core problems you'll have to deal with is managing and synchronizing the state of your application throughout all its components.
Let's consider a simple example, an application which takes two numbers, entered by the user, and displays their sum. The application consists of two text input fields. The sum should be recomputed and redisplayed whenever the values entered in the fields change. This application consists of four components:
- The two input fields
- The UI element in which the resulting sum is displayed, i.e the display component
- The internal component which is responsible for computing the sum
The internal component needs to know what the values entered in the input fields are, in order to compute their sum. In other words the internal component is dependent on the state of the two input fields. The UI element in which the sum is displayed, needs to know what the sum is and is thus dependent on the state of the internal component, which is responsible for computing the sum.
When the values in the input fields are changed, the internal component needs to be notified of this change in order to recompute the sum. Likewise the display component needs to be notified of the new sum, in order for it to be displayed. This updating of the state in response to user events encompasses the State Management Problem.
Solutions
Today's programming languages offer a number of common solutions to the state management problem.
Imperative Programming
The most basic solution is that offered by imperative programming languages. An imperative language, such as Java or C/C++, provides direct access to the underlying memory. This means the programmer can read and write to memory with few restrictions. In an imperative language, an object references a location in memory where a value, or a series of values are stored and can be modified. A modification to that object will be visible to all references to the same object. In effect, the memory comprises the application's state.
With imperative programming, a typical implementation, of the sum application, involves attaching event listeners to both fields, which are called whenever their values change. In the event listener, the value entered in the text field is read from memory, and stored in a variable, a reference to another memory location, which is accessible to the internal sum component. A procedure is called to recompute the sum. This procedure reads the values of the internal variables, which store the values entered in the text fields, and computes the new sum. Finally this new sum has to be written to the memory, in which the value displayed to the user, is stored.
The problem with this approach is that the synchronization of the application state, across all its components, is left entirely up to the programmer. This quickly becomes repetitive and the application logic is buried under layers of state updating and synchronization code.
This approach is also inflexible to changes in the application's specification. For example, consider that we want to enhance the application, such that if the sum exceeds a limit, provided by the user, a "Limit Exceeded" message is displayed. In essence this involves the addition of a new application component. To do so we'd have to modify the code for the internal component, which is responsible for computing the sum, in order to inform the new component of changes to the sum.
Finally this approach is prone to bugs in which, if a component is not properly notified of a change in the state of another component, the application state is not properly updated. Further room for bugs is created, when multi-threading is added to prevent the user interface from becoming unresponsive in long-running computational or IO tasks. Now the programmer has to worry about synchronizing the application state across multiple threads.
Functional Programming
Functional programming differs from imperative programming in that it does not provide the notion of memory. In a functional programming language, an application is composed of pure functions, which take a number of inputs and produce an output. This output is then fed on to further functions which produce further outputs. In a functional programming language, objects do not reference a memory location where a value is stored, rather the object is the value itself. An object cannot be modified, only a new object can be created. By eschewing memory, functional programming eschews application state completely. Without state, applications which interact with the user, while they are running, cannot be implemented.
To workaround this limitation, the entire application is structured as a pure function of its input, which is an infinite stream of user events. The function maps this stream to the stream of resulting application states. It is this output stream which is observed by the user.
Using this approach the sum application would be implemented as a function which takes the values of the two text fields as input and produces an application object as output in which the sum of the two values is displayed. This function is called whenever the user interacts with the application, i.e. when the values entered in the text fields are changed, and the resulting application object, which is identical to the previous application object with the only difference being that the sum is updated, is displayed.
This approach improves on the imperative approach in that the application code consists of just the application logic, itself. There is no state updating, or state synchronization code as there isn't any state to begin with. The problem with this approach is that what is inherently a stateful problem, the application itself, has to be artificially contorted into a pure function on a stream of events. The programmer can no longer think of the application as it is at a given moment in time but rather has to think about computing what the application is at any moment in time.
Functional Reactive Programming
The third solution, which is the approach taken by Tridash, is closely related to the second, however the notion of memory is brought back. Instead of eschewing memory and state completely, each application component, called a node in Tridash, has a state. However unlike with the imperative approach, this state cannot be arbitrarily modified. Instead the state of each component is specified as a pure function of the state of the components on which it depends. Whenever the state of a component changes, the state of all components which depend on that component is recomputed. In Tridash, this relation between a component (node) and its dependencies is referred to as a binding.
The implementation of the sum application is thus a matter of declaring each component, declaring that the value of the internal sum component is the sum of the values entered in the fields, and declaring that the value displayed as output is the value of the sum component.
In Tridash the entire application, excluding the user interface, can be implemented with the following:
a <- input-a.value
b <- input-b.value
sum <- a + b
output <- sum
where the <- operator specifies that the value of the node on the
left-hand side is bound to the value of the node/expression on the
right hand side.
Functional reactive programming has the advantages of regular functional programming however a more natural, stateful, view of the application is presented. Instead of thinking about how the inputs map to the internal representation of the application object, and how that object maps to the output, which is the state of the user interface, the programmer can think in terms of how does the state of this component relate to the state of the remaining components.
Functional reactive programming (FRP) has the disadvantage however, that there is no way to cleanly specify that a component is dependent on its past states. As an example, implementing a counter, which is incremented by one whenever a button is pressed is impossible. Most FRP systems simply degenerate to the stream of user events approach, of regular functional programming when it is necessary to map a previous state of a component to a new state.
Node States and Stateful Bindings with Tridash 0.8
Tridash 0.8 introduces two new features, Node States and Stateful Bindings, which allow mapping a past state of a component (node) to its current state, without leaving the functional reactive programming paradigm.
In Tridash, bindings are established using the -> operator, or the
<- operator, as seen above, which is the same operator but with the
arguments reversed.
a -> b
In this example, a binding is established between node a and node
b. Whenever the value of a changes, the value of b is
automatically updated to it.
However, this does not allow mapping a previous state to the current
state, i.e. a cannot be a function of b. Implementing a counter
with the following will not work.
counter + 1 -> counter
The reason being, that this specifies that whenever the value of
counter + 1 changes, the value of counter is updated to
it. However when the value of counter is updated, the value of
counter + 1 is also recomputed and updated. This results in the
value of counter being updated again which results in yet another
recomputation of counter + 1. Its obvious that the simple rule of
updating the value of counter whenever the value of its dependency,
counter + 1 in this case, changes will not do. We need a way to tell
the language when we actually want counter's value to be updated.
Node states allow a node to be given an explicit named state at a
given moment in time. The state is named by a symbol identifier. A
stateful binding is a binding which only takes effect when a node
switches to a particular named state. A stateful binding is
established when the observer node in a binding, the node on the right
hand side of the -> operator, is given an explicit state, using the
:: operator.
a -> b :: state
In this example, a stateful binding is established which takes effect
when b switches to the state with identifier state. a can be a
function of b as the binding only takes effect when the state of b
changes to state and not when the value of a is changed.
A counter can be implemented with the following stateful binding:
counter + 1 -> counter :: increment
Node counter is thus incremented when its state changes to
increment.
All that remains is to actually set the state of counter. What
determines the state of a node? Simple, the value of the special node
/state(node), where node is the node identifier. To set the state
of counter we simply establish a binding with /state(counter) as
the observer.
We want counter to be incremented whenever a button is
pressed. Let's say we have another node clicked? which has the value
true while the button is being pressed and false when it is
released. We can thus bind /state(counter) to an expression which
evaluates to the literal symbol increment when clicked? is true
and to something else, such as the symbol default when clicked? is
false. The following is the expression we require (to which
/state(counter) is bound):
case (
clicked? : '(increment),
'(default)
) -> /state(counter)
The ' operator simply returns its argument as a literal symbol,
similar to the ' or quote operator in Lisp.
User Inteface
The application logic is complete, the only thing missing is the user interface. The interface can be defined with the following HTML:
<div>Value of counter is <?@ counter ?></div>
<button id="increment">Increment</button>
With the current version of Tridash the value of the clicked? node
has to be set manually via JavaScript when the button is clicked. In
the next version, you'll be able to bind to a node that is
automatically set to true when the button is pressed and false when it
is release.
To be able to reference the clicked? node from JavaScript the
following attribute declaration are required:
/attribute(clicked?, input, 1)
/attribute(clicked?, public-name, "is_clicked")
This designates clicked? as an input node and gives it the
identifier is_clicked, with which it is referenced from JavaScript.
The following JavaScript script tag is required to attach an event listener to the button and set the value of the node.
<script>
var button = document.getElementById('increment');
button.addEventListener('click', function() {
Tridash.nodes.is_clicked.set_value(true);
Tridash.nodes.is_clicked.set_value(false);
});
</script>
The first line gets a reference to the HTML button element. The
remainder of the code attaches the event listener for the click
event, and sets the value of the clicked? node to true and then
immediately false. We're setting to false after setting it to true in
order to mimic the behaviour of a button.clicked? node, which will
be added in the next release.
To put it all together we place the Tridash code in a Tridash code tag at the top of the HTML file:
<?
/import(core)
counter + 1 -> counter :: increment
case (
clicked? : '(increment),
'(default)
) -> /state(counter)
# Initial Value of Counter
0 -> counter
# Attribute for reference `clicked?` node from JavaScript
/attribute(clicked?, input, 1)
/attribute(clicked?, public-name, "is_clicked")
?>
<!doctype html>
<html>
<head>
<title>Counter</title>
</head>
<body>
<h1>Counter</h1>
<div>Value of counter is <?@ counter ?></div>
<button id="increment">Increment</button>
<script>
var button = document.getElementById('increment');
button.addEventListener('click', function() {
Tridash.nodes.is_clicked.set_value(true);
Tridash.nodes.is_clicked.set_value(false);
});
</script>
</body>
</html>
This is the complete application implemented using the Functional Reactive Programming paradigm (excluding the JS script tag which is only necessary in the current version):
The following command builds the application:
tridashc counter.html : node-name=ui -o app.html -p type=html -p main-ui=ui
Here a snapshot of the initial state (with the initial value of 0
given to counter):

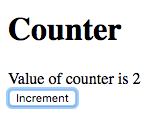
After pressing Increment once:

After pressing Increment again:
Conclusion
Tridash 0.8 adds two novel features which extends the simple Functional Reactive Programming paradigm to allow for implementing stateful applications, in which the state of an application component depends on its previous state rather than the state of another component. This retains all the advantages of functional programming however provides a natural model of application state.
For more information about Tridash (installation instructions, documentation tutorials) visit https://alex-gutev.github.io/tridash/.
For a more detailed and feature rich example, as well as examples of stateful bindings with explicit From and To states, visit: https://alex-gutev.github.io/tridash/tutorials/ar01s10.html.







